Introduction
In this third episode of the Backtesting Series, we will explore the broad space of Factor Models. If you haven’t already, we recommend reading the first two episodes before proceeding with this article. Please note that the series will include the following parts:
- Part 1: Introduction
- Part 2: Cross-Validation techniques
- Part 3: Factor Models
- Part 4: Portfolio Construction & Portfolio Optimization
- Part 5: Backtest Analysis
- Part 6: Introducing TCs, assessing capacity, preparing for production
Factor Models and their History
A factor model is a mathematical framework used to explain returns by expressing them as a function of factors. In general, factors are drivers of the returns of a particular asset. Factor Models take the form of:

Where:
 denotes the discrete time period;
denotes the discrete time period; is the vector of asset returns;
is the vector of asset returns; is a vector of constant values that does not contribute to the overall volatility;
is a vector of constant values that does not contribute to the overall volatility; is the vector of factor returns;
is the vector of factor returns; is the loading matrix;
is the loading matrix; is the vector of idiosyncratic returns.
is the vector of idiosyncratic returns.
To give you some common examples, one of the first formal models linking a given asset’s returns to its level of risk is CAPM. Introduced by Sharpe, Lintner, and Mossin in the 1960s, CAPM formalized the relationship between expected returns and systematic risk as:

Where the  (the loading) describes the sensitivity of the asset’s returns to the market premium.
(the loading) describes the sensitivity of the asset’s returns to the market premium.
In 1993, Eugene Fama and Kenneth French published a revised model of CAPM, adding two new factors describing the expected returns called size and value. Their model showed first that the returns of smaller equities are proportionally higher than larger equities, and second, that equities whose ratio of market value to intrinsic value is smaller show superior performance to those where the market value was relatively higher than the intrinsic value. It is worth noting that stocks with a smaller ratio are commonly referred to as value stocks and those with a higher ratio growth stock. The Fama-French equation is given by:

Where SMB (“small minus big”) represents the excess return of small-cap stocks over large-cap stocks (size factor), and HML (“high minus low”) represents the excess return of value stocks over growth stocks (value factor). Moreover, each factor has its unique  that composes the loading matrix
that composes the loading matrix
“In the years that followed, extensive research on this topic led to significant advancements in financial modeling. These studies extended the initial concepts to develop more generalized models, introducing the idea of incorporating multiple factors that could influence asset prices. This evolution paved the way for what is now known as the general factor model, which provides a comprehensive framework for analyzing the impact of various economic and financial factors on asset returns. Mathematically:

Why are Factor Models Useful?
Factor models are useful for four main reasons: risk measurement, risk decomposition, performance attribution, and hedging. By decomposing an asset’s returns into a finite number of factors, one can measure the sensitivity of the asset to systematic risks and distinguish it from idiosyncratic risks. This decomposition enables investors to assess which portion of the return is driven by broad market dynamics (systematic risk) and which is due to factors unique to the asset (idiosyncratic risk). This insight is critical for constructing diversified portfolios and understanding the sources of risk and return.
Factor models play a crucial role in risk measurement by quantifying the exposure of an asset or portfolio to specific risk factors such as market movements, size, or value. For instance, the Capital Asset Pricing Model (CAPM) beta measures how sensitive an asset’s return is to overall market movements. Multi-factor models go beyond this by incorporating additional risks, enabling more comprehensive risk assessments. This quantification aids in forecasting potential losses under varying market conditions.
In addition to measuring risk, factor models facilitate risk decomposition by breaking down a portfolio’s overall risk into components attributable to different factors. A portfolio might derive 70% of its risk from market movements, 20% from size, and 10% from value. This decomposition helps investors fine-tune their exposure to particular risks or mitigate unwanted risks through diversification or hedging strategies.
Performance attribution is another key application of factor models. These models help distinguish whether a portfolio’s performance results from the manager’s skill—known as alpha—or from exposure to certain risk factors. For instance, if a portfolio outperforms its benchmark, a factor model can determine if the excess return arises from superior stock selection or higher exposure to factors like size or value.
Lastly, factor models are instrumental in constructing hedging strategies. By analyzing an asset’s factor exposures, investors can design strategies to offset specific risks using derivatives or other financial instruments. For example, if a portfolio is significantly exposed to market risk, an investor can use index futures to hedge against this risk while maintaining other factor exposures. Through these applications, factor models provide investors with a versatile toolkit for managing risk.
Fundamental Model for Equities
A fundamental factor model is a specific type of factor model designed to explain stock returns by relating them to observable, interpretable variables rooted in the economic or financial characteristics of companies. These models decompose stock returns into contributions from a set of fundamental factors and idiosyncratic residuals. The goal is to identify and quantify systematic sources of risk and return.
Step 1: Defining the Factors
When constructing a Fundamental Factor Model for equities, the primary goal is to explain the cross-sectional variation in stock returns through fundamental, interpretable factors. These factors are chosen based on their theoretical and empirical significance in explaining equity returns.
The key inputs to generate the factor loadings matrix  include:
include:
- A set of asset returns
- A set of raw characteristics per asset.
Through transformation and combination of this inputs is possible to get a loading matrix , although when working with raw characteristics it is important to take care of their structure. In fact, the task of extracting structured data from unstructured information is perhaps the one that requires the highest amount of human intelligence.
Step 2: Regression Framework
Once we have defined factors and built the loading matrix , the next step is to perform a cross-sectional regression on the estimation universe:

Where the parameters to be estimated are and , the vectors of factors and idiosyncratic returns.
Step 3: Model Evaluation
To evaluate the effectiveness of factor models, it is essential to assess the explained variance, residual analysis, and the interpretation of factor returns. The explained variance measures the proportion of total return variance accounted for by the factors. This is typically quantified through the calculation of the R^2 value in regression analysis, which provides insight into the overall explanatory power of the model.
Residual analysis involves examining the residuals to ensure they are uncorrelated and lack significant systematic structure. This step is critical for identifying potential issues, such as missing factors or data problems, that could undermine the model’s accuracy. Large residuals often signal deficiencies in the model or overlooked variables that should be included.
Finally, Analyzing the time series of factor returns allows for a deeper understanding of how various factors behave under different market conditions or during sectoral rotations. This comprehensive evaluation ensures that the factor model is robust, reliable, and capable of effectively capturing the complexities of asset returns.
Fundamental Factor Model for Rates – Introduction
When constructing a Fundamental Factor Model for Rates, the primary question to address is: how can the term structure of interest rates be accurately estimated? Indeed, estimating the term structure of interest rates is a fundamental step in constructing a robust Rates Fundamental Factor Model. A precise estimation of the term structure allows for the decomposition of rate variations into fundamental factors, enhancing the model’s ability to assess risk. Without an accurate and reliable estimation of the term structure, the model’s effectiveness is significantly compromised, limiting its applicability. Therefore, the accuracy and reliability of a Rates Fundamental Factor Model are inextricably tied to the effective estimation of the term structure, underscoring its importance as a critical foundation for understanding and managing the complexities of interest rate markets.
The Data
For the estimation of the term structure and the development of our rates fundamental factor model, we utilized a comprehensive dataset comprising daily data on U.S. Treasury bonds obtained from Bloomberg. This dataset includes detailed information on bond yields, time to maturity, coupon rates, maturity dates, dv01, and prices. For computational reasons the dataset was shrinked the past 10 years.
Nelson-Siegel Model for the estimation of Term Structure
To address the challenge of estimating the term structure of interest rates, we selected the Nelson-Siegel (1987) model, a widely used and flexible approach for yield curve estimation. This model is particularly effective in generating the term structure due to its ability to fit a broad range of yield curve shapes by capturing the three key components: level, slope, and curvature. Our choice of the Nelson-Siegel model was influenced not only by its flexibility but also by the structure of our initial dataset. The dataset, comprising daily information on U.S. Treasury bonds, had gaps in the term structure that required an effective interpolation technique to achieve a complete and accurate estimation. The Nelson-Siegel model provided an optimal solution for filling these gaps, ensuring consistency across the term structure while maintaining computational efficiency. Its ability to bridge missing segments and align with the characteristics of our dataset made it the most appropriate choice for our factor modeling needs.
Getting more in depth with how it is built, the Nelson-Siegel Model is a parametric model that can use the Yield curve factors to estimate the entire term structure. This model uses three factors, and they can be interpreted as level, slope, and curvature. It is defined as follows:
![y\left(T\right)=\beta_0+\beta1\left[\frac{1-exp\left(-T/\lambda\right)}{T/\lambda}\right]+\beta_2\left[\frac{1-exp\left(-T/\lambda\right)}{T/\lambda}-exp\left(-T/\lambda\right)\right]](https://bsic.it/wp-content/ql-cache/quicklatex.com-b7ae69ba0ec11eab03d0246e5b14e8c5_l3.png "Rendered by QuickLaTeX.com")
Where:
 is the yield at time to maturity
is the yield at time to maturity 
 are loadings that respectively influence the level, the slope and the curvature of the yield curve.
are loadings that respectively influence the level, the slope and the curvature of the yield curve. is a scale parameter that represents the speed at which interest rates converge to the long-term average.
is a scale parameter that represents the speed at which interest rates converge to the long-term average.
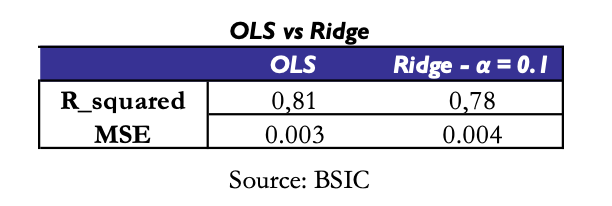
Despite the longevity of this model, the estimation process of its parameters is still argument of open debate. To do that we pursued two different approaches using either OLS loss function and Ridge loss function to account for multicollinearity. So, we estimated our set of parameters  in one of this two ways:
in one of this two ways:


Where is the parameter that controls the amount of shrinkage. Below are reported out of sample performance metrics of the two estimation methods:

First application: decomposition in Carry and Rolldown
We defined the gross returns  of a bond from time to
of a bond from time to  as the total value at the end of the period minus the starting value all divided by the starting value. Mathematically:
as the total value at the end of the period minus the starting value all divided by the starting value. Mathematically:

Where  is the coupon rate and
is the coupon rate and  is the price at time .
is the price at time .
Building on the initial definition of returns, we further decomposed these returns into carry and roll-down components to provide a clearer understanding of the sources of bond returns such that:

Where  represent the idiosyncratic returns.
represent the idiosyncratic returns.
While the computation of carry is relatively straightforward, the calculation of roll-down is more nuanced and involves several key assumptions.
The roll-down return measures the change in the bond’s price due to the passage of time as it “rolls down” the yield curve, assuming no change in the underlying term structure. Then, to approximate the actual roll-down return, it is necessary to project the bond’s price at a future point in time. This requires estimating the bond’s new yield, maturity, and price as time advances. A crucial component of this process is the assumption about the shape and dynamics of the yield curve over time. Here is where having a robust term structure model becomes crucial. In our analysis, the Nelson-Siegel model was applied to estimate the yield curve at various points in time.
To assess the effectiveness of our return decomposition, we performed a rolling regression of actual bond returns against the sum of carry and roll-down components:

This analysis yielded an average beta of approximately 0.997.
An average beta so close to 1 suggests the presence of an actual correlation between estimated carry and rolldown and bond returns. In practical terms, the near-perfect beta implies that our assumptions about the term structure and the methodology used for calculating roll-down were robust and accurately aligned with market behavior during the analyzed period. This demonstrates that our decomposition approach provides a reliable framework for understanding and forecasting bond return dynamics.
Returns decomposition
Going on with building our factor model, we conducted a decomposition of bond returns into systematic and idiosyncratic components using the factor scores derived from the Nelson-Siegel model. The mathematical structure of this decomposition is represented as:

The regression quantifies the factor returns, and separates the factor-driven returns (systematic returns) from the idiosyncratic returns. In this case, the systematic returns are those explained by exposure to the level, slope, and curvature factors, while the idiosyncratic returns represent the portion of returns unique to each asset that cannot be explained by the factor model.
This decomposition is a critical step in constructing two key covariance matrices for risk analysis. The systematic returns obtained from the factor exposures are used to compute the factor covariance matrix, which captures the co-movement and volatility of the systematic risk factors. This matrix is essential for understanding how these factors interact and impact overall portfolio risk. Concurrently, the idiosyncratic returns are used to estimate the idiosyncratic covariance matrix, which measures the variance and correlations of asset-specific risks. Together, these matrices form the foundation for risk decomposition and portfolio optimization.
One of the most notable results from the regression was achieving an average R squared of 0.81 across the dataset. This indicates that 81% of the variation in bond returns is explained by the systematic factors of the model—level, slope, and curvature. Such a high average beta demonstrates the model’s effectiveness in capturing the true drivers of bond returns. A high beta is particularly desirable when constructing a factor model, as it shows that the factors chosen are well-aligned with the actual economic dynamics influencing returns. This reinforces the model’s validity as a framework for analyzing risk.
In practice, the high explanatory power implied by the 0.81 average R squared improves the reliability of the factor covariance matrix and the idiosyncratic covariance matrix, which are critical tools for risk management. A robust factor model with strong systematic explanatory power provides a stable foundation for understanding and managing risk over time. This outcome highlights the Nelson-Siegel framework’s practical value in risk modeling, ensuring that portfolios can be optimized and managed effectively in response to the systematic and idiosyncratic risks they face.
Covariance Matrix estimation with Fundamental Model
Once we have computed the cross-sectional regression, we will end up having a vector of factor returns  and a vector of idiosyncratic returns
and a vector of idiosyncratic returns  , from which we want to estimate the factor and idiosyncratic covariance matrix
, from which we want to estimate the factor and idiosyncratic covariance matrix  and [/latex] \Omega_\epsilon [/latex].
and [/latex] \Omega_\epsilon [/latex].
Given  , the matrix of factor returns where
, the matrix of factor returns where  , the estimation of the factor empirical covariance matrix is pretty straightforward as:
, the estimation of the factor empirical covariance matrix is pretty straightforward as:

To estimate the covariance matrix of idiosyncratic returns  based on estimated idiosyncratic returns , as in Paleologo (2024), we use exponential weighting. Let
based on estimated idiosyncratic returns , as in Paleologo (2024), we use exponential weighting. Let  be the matrix of estimated idiosyncratic returns with
be the matrix of estimated idiosyncratic returns with  . On the other hand, the weighting matrix is a diagonal positive definite matrix, and we denote it with
. On the other hand, the weighting matrix is a diagonal positive definite matrix, and we denote it with  . Given an exponential weighting parameter
. Given an exponential weighting parameter  the diagonal terms of are computed as:
the diagonal terms of are computed as:
![\left[W_\tau\right]_{t,t,}=\kappa exp\left(-t/\tau\right)](https://bsic.it/wp-content/ql-cache/quicklatex.com-c69487e4e48f5a2628e9fbf48e5f3687_l3.png "Rendered by QuickLaTeX.com")
Where the positive constant  ensures that the diagonal terms sum to . Then the EWMA empirical idiosyncratic covariance matrix is defined as:
ensures that the diagonal terms sum to . Then the EWMA empirical idiosyncratic covariance matrix is defined as:

Once estimated factor and idiosyncratic covariance matrix, they can be used to approximate the overall returns covariance matrix as:

Statistical Factor Models
In the statistical model framework, we assume to know neither the factor returns, nor the exposures and we have to estimate both. The estimation relies on Principal Component Analysis. Indeed, the PCA solution constitutes a good approximation and converges in the limit to the true model. There are several compelling reasons for developing a statistical factor model. First and foremost, in certain asset classes, firm-specific characteristics or macroeconomic factors may be unavailable. In such scenarios, where returns are the only accessible data, statistical factor models become an essential approach. Furthermore, even if factor returns were available, they might be less relevant at very short time scales, such as intraday intervals measured in minutes. Additionally, employing diverse models offers significant analytical benefits. It enables the identification and examination of the weaknesses and limitations inherent in individual models. This is particularly valuable in portfolio optimization, where using various models to constrain factor variance and compare alternative solutions contributes to more robust and reliable optimization outcomes.
On the other hand, the main disadvantage of statistical models is that their loadings are less interpretable than in the case of alternative estimation methods. The first factor is usually the easiest to interpret as the whole market while the others can find different interpretations.
Starting from X, a matrix  of returns of
of returns of  assets over periods, the construction of the factor model through Principal Component Analysis proceeds as follows. PCA can also be performed through Singular Value Decomposition (SVD), but we will outline the method using the sample covariance matrix below:
assets over periods, the construction of the factor model through Principal Component Analysis proceeds as follows. PCA can also be performed through Singular Value Decomposition (SVD), but we will outline the method using the sample covariance matrix below:
- Demean the data, as PCA assumes the data is centered. Additionally, the data can be also standardized, in which case the PCA is applied to the correlation matrix, rather than the covariance matrix. This is a non-trivial choice, as one could argue that the correlation matrix behaves differently from the covariance matrix, thus requiring different hyperparameters (e.g. the window of the PCA)

- Compute the covariance matrix of the standardized data:

- Decompose the covariance matrix into eigenvalues and eigenvectors, where eigenvalues represent the amount of variance explained by each principal component and eigenvectors provide the directions that define the principal components.
- Select the first
 components that explain the largest amount of variance, so the ones with the biggest eigenvalues. will represent to the number of factors retained. The eigenvectors corresponding to the first components form the loadings matrix
components that explain the largest amount of variance, so the ones with the biggest eigenvalues. will represent to the number of factors retained. The eigenvectors corresponding to the first components form the loadings matrix  , which has dimension
, which has dimension  .
. - Once you have a matrix of loadings corresponding to the components, the next step is to get the Factor Returns matrix . It can be directly computed from the loading matrix and the standardized asset returns matrix as:

- Factor returns can then be used to build a factor model that expresses our original returns as a combination of factorial and idiosyncratic variance. The matrix
 can be reconstructed as follows:
can be reconstructed as follows:


Where is the idiosyncratic variance, or the variance in not explained by the factors.
Statistical Model for Rates
For the statistical model on rates, we consider US Treasuries dating back to 2000. We run the PCA on the sample covariance matrix of returns (hence without standardizing). We remind you that we are still assuming the following form for our factor model:

Where, in this case, will be our loadings matrix, containing our eigenvectors as columns, and will comprise of our factor returns (the PCs).
There is a major issue compared to a normal PCA, which we think is important to point out: our universe changes over time, bonds are issued and expire during our dataset, so we need to store the historical universe used to train our model.
Furthermore, the estimated eigenvalues from a normal PCA are biased upward, which would impact our covariance estimates. Thus, if we assume normally distributed factor and idiosyncratic returns, we can use Probabilistic PCA (PPCA), which shrinks our eigenvalues and consequently our covariance matrix, thus reducing the bias in the model. This is far from a perfect solution, and there are other methods for shrinking the eigenvalues, which are outlined extensively in Paleologo (2024).
If using PPCA, it can be derived that



Where  is our loadings matrix, containing the first m eigenvectors,
is our loadings matrix, containing the first m eigenvectors,  is a diagonal matrix containing the first m eigenvalues, and
is a diagonal matrix containing the first m eigenvalues, and  is the mean of the omitted eigenvalues (from m to n).
is the mean of the omitted eigenvalues (from m to n).  is the covariance of our factors and of our idiosyncratic returns, respectively. Thus, the estimated covariance matrix for our returns is
is the covariance of our factors and of our idiosyncratic returns, respectively. Thus, the estimated covariance matrix for our returns is

Factor hedging
Let suppose that you have a portfolio that is not optimized, and that exhibits undesired systematic risk. In this case, the hedging process seeks to reduce the unwanted risk from factor exposures. A common way to hedge this unwanted risk is to first compute the factor exposure  as
as  and then we trade out the core exposure by buying an amount of factor exposure
and then we trade out the core exposure by buying an amount of factor exposure  . We can do this by buying a hedge portfolio with weights computed as follows:
. We can do this by buying a hedge portfolio with weights computed as follows:  where
where  is the matrix whose columns are the Factor-Mimicking Portfolios associated with the factor model.
is the matrix whose columns are the Factor-Mimicking Portfolios associated with the factor model.
Since Factors are purely theoretical and cannot be directly traded, Factor-Mimicking Portfolios are those that given a factor try to have returns as close as possible as the ones of the factor. In other words, Factor-Micking Portfolios are those that minimize the variance of the difference between their returns and the ones of the corresponding factor . The factor-mimicking portfolios allow us to translate factor exposures into actual portfolio weights or positions that hedge or replicate those exposures.
Conclusions
In conclusion, factor models have proven to be indispensable tools in modern financial analysis, offering a structured approach to understanding the underlying drivers of asset returns. From risk measurement and decomposition to performance attribution and hedging, these models provide investors with a robust framework for managing portfolio risks and optimizing performance. The detailed methodologies explored, including fundamental and statistical factor models, demonstrate the versatility and depth of these tools in both equity and rates markets.
As we transition into the next episode of this series, we will delve into portfolio construction and optimization. This will include exploring how factor models integrate into practical portfolio strategies and the advanced techniques used to optimize returns while managing risk. Stay tuned for an in-depth discussion on building portfolios that leverage the insights gained from factor-based frameworks.
References
- Paloeologo, Giuseppe, “The Elements of Quantitative Investing”, 2024
- Paloeologo, Giuseppe, “Advanced Portfolio Management”, 2021
- Annaert, Claes, De Ceuster, Zhang, “Estimating the Yield Curve with the Nelson-Siegel Model”, 2015


0 Comments